
IBM 1401 core memory
2016-07-19
Originally published on Medium.
Reverse proxy routers mysteriously segfault. Docker ignores your cries for a core dump. Stack Overflow quietly smirks at your solitary misfortune. You can retreat to defetal position and give up on your microservices dream, or you can pick up your gdb, face down Docker, and go to war.
Production is war, and war is hell. — Bryan Cantrill, Dockercon 2015
IBM 1401 core memory
In early May your team visited the Computer History Museum and enjoyed a lovely demonstration of a restored IBM 1401.
The operators indulged your many questions and showed off internals like core memory modules.
For troubleshooting, they could print out (on paper) the entire contents of this core memory — a core dump.
This makes you sad.
The previous week, you observed troubling syslog entries in Kibana.
kernel: [4838261.071917] haproxy[610]: segfault
at 7fdb0426e000 ip 00007fdb0403305b sp 00007ffee5ff8988 error 4
in ld-musl-x86_64.so.1[7fdb03fe2000+87000]
And that’s it. Segfault and no core dump. IBM 1401 operators in 1959 could get a core dump and you can’t get one out of your fancy-pants microservices platform. Why? Because Docker. Well, Docker on Ubuntu. HAProxy runs in a Docker container on an Ubuntu host, and you can’t have nice things.
This is why you are sad. To stop being sad and get nice things, keep reading.
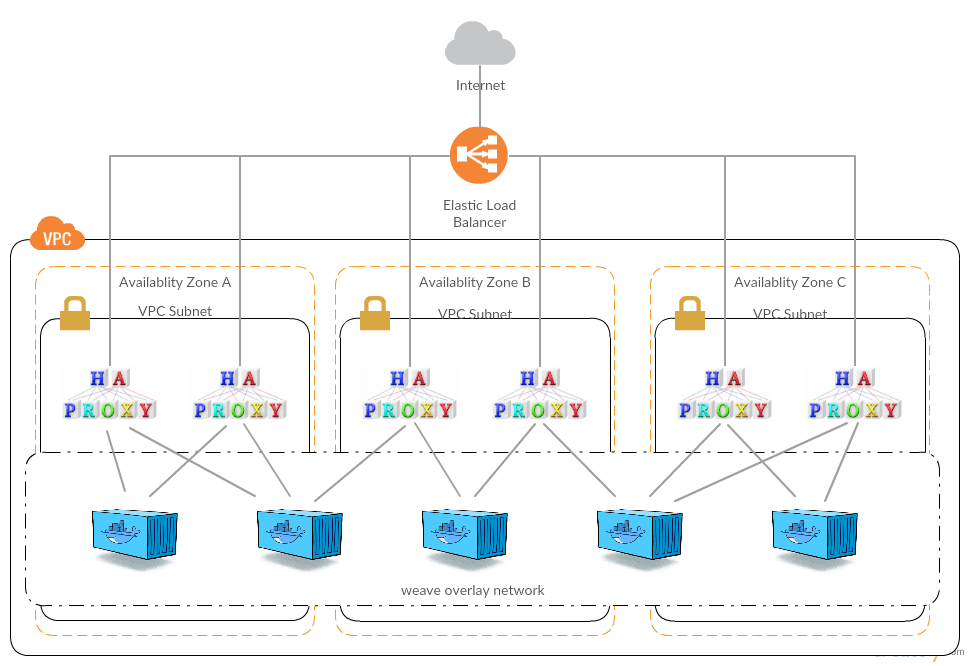
Udacity platform network diagram
Since December 2015, Udacity is transitioning from Google App Engine to a highly available microservices platform. It is state-of-the-art, infrastructure-as-code, Mesos, Docker, Consul, Weave Net (OvS), buzzword all the things. The key to this transition is an HAProxy routing layer that dynamically reacts to service discovery changes and routes traffic to microservices in Docker containers on an OvS overlay network — every container gets an IP. One of those microservices is itself a router, fronting for the legacy app on GAE. In front of all that, an AWS Elastic Load Balancer keeps ingress distributed between AWS Availability Zones.
Segfaults are happening in that critical HAProxy routing layer one every five minutes on average.
Absent a core dump, to DataDog!
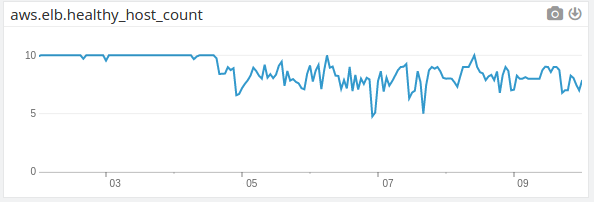
healthy host count over several days
So what happened between days 3 and 5?
A new microservice went live and a similar one a month later — you can call them Things One and Two. Each Thing serves web-hooks for Segment.io and gets lots of traffic. By overlaying DataDog graphs and request logs from Kibana, you observe correlations between segfault rates and traffic from Segment. You also see segfaults correlate to service deployments. This is telling because service deployments trigger HAProxy routing layer changes.
Since Thing One isn’t critical, you turn it off. That helps but the segfaults don’t go away and they don’t only happen near deployments. You still have no firm causal links.
If you choose to shake down Docker for a core dump, continue reading.
Your HAProxy servers run inside Docker containers on Ubuntu hosts and this is a problem. Since all containers share a kernel and thus kernel settings in /proc/sys, Ubuntu’s default of piping core dumps to Apport is inflicted on all hosted containers. And, most containers don’t include Apport. To mitigate:
$ echo 'core.%e.%t.%p' | sudo tee /proc/sys/kernel/core_pattern
docker daemon [...] --default-ulimit core=-1
Next, you create a custom haproxy container built with debug symbols, HAProxy source code, and gdb. You deploy this to a canary and wait.
While you wait for core dumps, you may want to learn more about gdb. Choose to learn more and keep reading.
gdb lets you see what is going on inside a program while it executes — or what the program was doing at the moment it crashed. It is the latter in which you are most interested now. A crash course on gdb can be completed in 15 minutes; by then your core dumps will be hot and ready.
Here is a gdb session exploring the segfault
The terminal recording (above) captures driving your HAProxy segfaults to root cause, teaching some gdb along the way! To summarize …
(gdb) backtrace
#0 in memcpy () from /lib/ld-musl-x86_64.so.1
#1 in ?? () from /lib/libz.so.1
#2 in ?? () from /lib/libz.so.1
#3 in deflate () from /lib/libz.so.1
#4 in deflate_flush_or_finish (...) at src/compression.c:790
#5 in http_compression_buffer_end (...) at src/compression.c:249
#6 in http_response_forward_body (...) at src/proto_http.c:7173
#7 in process_stream (...) at src/stream.c:1939
#8 in process_runnable_tasks () at src/task.c:238
#9 in run_poll_loop () at src/haproxy.c:1573
#10 in main (...) at src/haproxy.c:1933
(gdb) frame 6
#6 in http_response_forward_body (...) at src/proto_http.c:7173
(gdb) print txn->uri
$3 = 0x55e95aff7a00 "POST /webhook/_REDACTED_FOUR_GREAT_SECURITAH__/ HTTP/1.1"
(gdb) frame 5
#5 in http_compression_buffer_end (...) at src/compression.c:249
(gdb) print *s->comp_algo
$6 = {cfg_name = 0x55e955ced5b0 "gzip", ...}
The segfault is happening while gzip compressing the end of a response to POST /webhook/… with zlib. Every core dump you examine happens while compressing a response from service Thing Two. If you choose to fix the routing layer so malformed responses don’t crash HAProxy …
Memory is getting overwritten someplace in zlib. This particular segfault isn’t showing up on Stack Overflow or Google, so there may be something unique to this combination of HAproxy, zlib, musl, and specific traffic.
The stock build of HAProxy on Alpine Linux is using zlib, but that’s not the best choice. HAProxy Enterprise Edition is built with libSLZ instead, boasting impressive memory and performance benefits. And, replacing zlib with libSLZ might fix the segfaults. If you choose to build a custom HAProxy with libSLZ, try this.
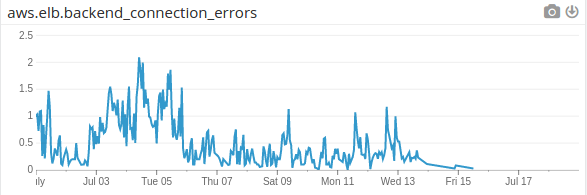
ELB connection errors/s
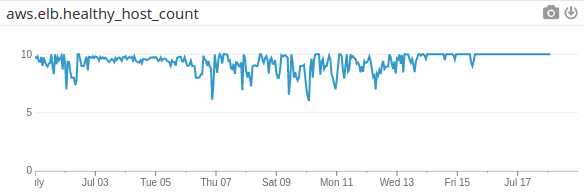
fix on Wed 13
This issue plagued us for several months, and time from discovery to fix was long. It only took a week in total to investigate, develop a fix, canary test, and deploy, but multiple P-0s and high priority projects preempted.
The 2-level load balancing architecture only bought us time. Amazon’s ELB masked issues in the HAProxy layer, although the instability certainly had adverse effects on our long tail latency. And as our microservices grew (we have over 100 in production), the instability grew accordingly.
Ability to debug in production is critical — it’s the only environment everyone cares about — and monitoring, metrics, and logs are necessary but not sufficient. In this brave new microservices world of “cattle not pets”, I see our industry sacrificing visibility on the altar of immutable infrastructure, naively depending on restarts as a cure-all for misbehaving services. Tools to reach in and see the state of our machines are as relevant today as they were in 1959.
Related tags:
email comments to paul@bauer.codes